






Apache Drill
Schema-free SQL Query Engine
for Hadoop, NoSQL and
Cloud Storage
DOWNLOAD NOW
AgilityGet faster insights without the overhead (data loading, schema creation and maintenance, transformations, etc.) |
FlexibilityAnalyze the multi-structured and nested data in non-relational datastores directly without transforming or restricting the data |
FamiliarityLeverage your existing SQL skillsets and BI tools including Tableau, Qlikview, MicroStrategy, Spotfire, Excel and more |

Query any non-relational datastore (well, almost...)
Drill supports a variety of NoSQL databases and file systems, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS and local files. A single query can join data from multiple datastores. For example, you can join a user profile collection in MongoDB with a directory of event logs in Hadoop.
Drill's datastore-aware optimizer automatically restructures a query plan to leverage the datastore's internal processing capabilities. In addition, Drill supports data locality, so it's a good idea to co-locate Drill and the datastore on the same nodes.
Kiss the overhead goodbye and enjoy data agility
Traditional query engines demand significant IT intervention before data can be queried. Drill gets rid of all that overhead so that users can just query the raw data in-situ. There's no need to load the data, create and maintain schemas, or transform the data before it can be processed. Instead, simply include the path to a Hadoop directory, MongoDB collection or S3 bucket in the SQL query.
Drill leverages advanced query compilation and re-compilation techniques to maximize performance without requiring up-front schema knowledge.
SELECT * FROM dfs.root.`/web/logs`; SELECT country, count(*) FROM mongodb.web.users GROUP BY country; SELECT timestamp FROM s3.root.`clicks.json` WHERE user_id = 'jdoe';
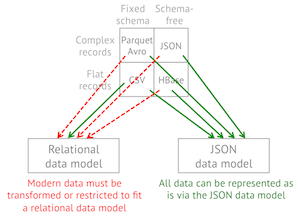
Treat your data like a table even when it's not
Drill features a JSON data model that enables queries on complex/nested data as well as rapidly evolving structures commonly seen in modern applications and non-relational datastores. Drill also provides intuitive extensions to SQL so that you can easily query complex data.
Drill is the only columnar query engine that supports complex data. It features an in-memory shredded columnar representation for complex data which allows Drill to achieve columnar speed with the flexibility of an internal JSON document model.
Keep using the BI tools you love
Drill supports standard SQL. Business users, analysts and data scientists can use standard BI/analytics tools such as Tableau, Qlik, MicroStrategy, Spotfire, SAS and Excel to interact with non-relational datastores by leveraging Drill's JDBC and ODBC drivers. Developers can leverage Drill's simple REST API in their custom applications to create beautiful visualizations.
Drill's virtual datasets allow even the most complex, non-relational data to be mapped into BI-friendly structures which users can explore and visualize using their tool of choice.

$ curl -L "<url>" | tar xzf - $ cd apache-drill-<version> $ bin/drill-embedded
Scale from one laptop to 1000s of servers
We made it easy to download and run Drill on your laptop. It runs on Mac, Windows and Linux, and within a minute or two you'll be exploring your data. When you're ready for prime time, deploy Drill on a cluster of commodity servers and take advantage of the world's most scalable and high performance execution engine.
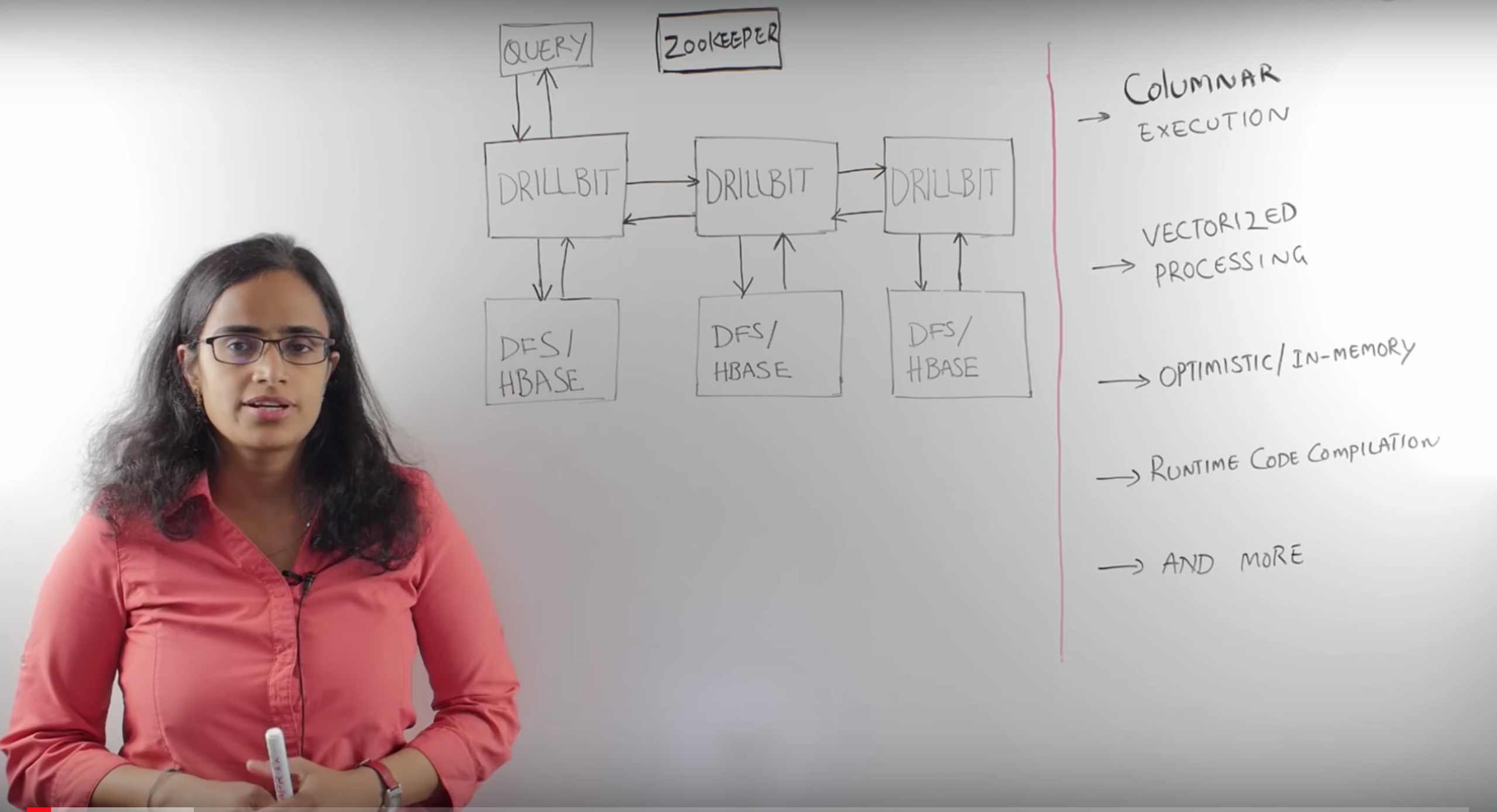
Drill's symmetrical architecture (all nodes are the same) and simple installation make it easy to deploy and operate very large clusters.
$ curl <url> -o drill.tgz $ tar xzf drill.tgz $ cd apache-drill-<version> $ bin/drill-embedded
No more waiting for coffee
Drill isn't the world's first query engine, but it's the first that combines both flexibility and speed. To achieve this, Drill features a radically different architecture that enables record-breaking performance without sacrificing the flexibility offered by the JSON document model. Drill's design includes:
- Columnar execution engine (the first ever to support complex data!)
- Data-driven compilation and recompilation at execution time
- Specialized memory management that reduces memory footprint and eliminates garbage collections
- Locality-aware execution that reduces network traffic when Drill is co-located with the datastore
- Advanced cost-based optimizer that pushes processing into the datastore when possible
