
Getting to Know the Drill Sandbox
This section covers key information about the Apache Drill tutorial. After installing the Drill sandbox and starting the sandbox, you can open another terminal window (Linux) or Command Prompt (Windows) and use the secure shell (ssh) to connect to the VM, assuming ssh is installed. Use the following login name and password: mapr/mapr.
For example:
$ ssh mapr@localhost -p 2222
Password:
Last login: Mon Sep 15 13:46:08 2014 from 10.250.0.28
Welcome to your Mapr Demo virtual machine.
Using the secure shell instead of the VM interface has some advantages. You can copy/paste commands from the tutorial and avoid mouse control problems.
Drill includes a shell for connecting to relational databases and executing SQL commands. On the sandbox, the Drill shell runs in embedded mode. After logging into the sandbox, use the SQLLine command. The Drill shell appears, and you can run Drill queries.
[mapr@maprdemo ~]$ sqlline
apache drill 1.1.0
"Does your data know the Drill?"
0: jdbc:drill:>
In this tutorial you query a number of data sets, including Hive and HBase, and files on the file system, such as CSV, JSON, and Parquet files. To access these diverse data sources, you connect Drill to storage plugins.
Storage Plugin Overview
You use a storage plugin to connect to a data source, such as a file or the Hive metastore. Take a look at the storage plugin definitions by opening the Storage tab in the Drill Web UI. Launch a web browser and go to: http://<IP address>:8047/storage.
The control panel for managing storage plugins appears.
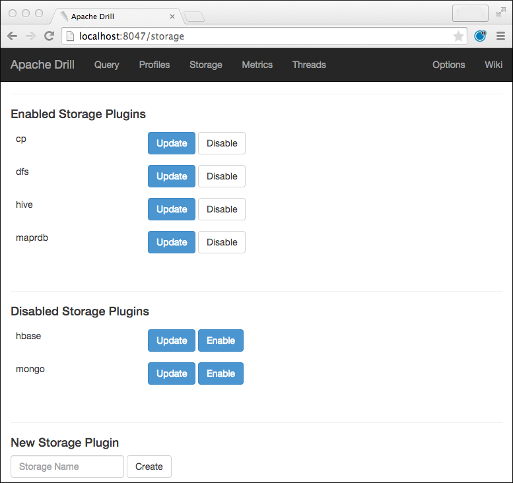
You see the following storage plugin configurations:
- cp
- dfs
- hive
- maprdb
- hbase
- mongo
Click Update to examine a configuration.
If you’ve used an installation of Drill before using the sandbox, you might notice that a few storage plugin configurations in the sandbox differ from the same storage plugin configurations in a Drill installation. The sandbox configurations of dfs, hive, maprdb, and hbase storage plugins definitions play a role in simulating the cluster environment for running the tutorial.
dfs
The dfs storage plugin in the sandbox configures a connection to the MapR file system (MapR-FS).
The dfs storage plugin configuration in the sandbox also includes a set of workspaces; each one represents a
location in MapR-FS:
- root: access to the root file system location
- clicks: access to nested JSON log data
- logs: access to flat (non-nested) JSON log data in the logs directory and its subdirectories
- views: a workspace for creating views
The dfs configuration includes format definitions.
{
"type": "file",
"enabled": true,
"connection": "maprfs:///",
"workspaces": {
"root": {
"location": "/mapr/demo.mapr.com/data",
"writable": false,
"defaultInputFormat": null
},
"clicks": {
"location": "/mapr/demo.mapr.com/data/nested",
"writable": true,
"defaultInputFormat": "parquet"
},
. . .
"formats": {
. . .
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
. . .
"json": {
"type": "json"
},
"maprdb": {
"type": "maprdb"
}
. . .
maprdb
The maprdb is a configuration for MapR-DB in the sandbox. You use this format in the sandbox to query MapR-DB/HBase tables.
hive
The hive configuration for a Hive data warehouse within the sandbox. Drill connects to the Hive metastore by using the configured metastore thrift URI. Metadata for Hive tables is automatically available for users to query.
{
"type": "hive",
"enabled": true,
"configProps": {
"hive.metastore.uris": "thrift://localhost:9083",
"hive.metastore.sasl.enabled": "false"
}
}
Do not use this storage plugin configuration outside the sandbox. Use the configuration for either the remote or embedded metastore configuration.
What’s Next
Start running queries by going to Lesson 1: Learn About the Data Set.