
Text Files: CSV, TSV, PSV
Best practices for reading text files are:
- Select data from particular columns
- Cast data
- Use a distributed file system
Select Data from Particular Columns
Converting text files to another format, such as Parquet, using the CTAS command and a SELECT * statement is not recommended. Instead, you should select data from particular columns. If your text files have no headers, use the COLUMNS[n] syntax, and then assign meaningful column names using aliases. For example:
CREATE TABLE parquet_users AS SELECT CAST(COLUMNS[0] AS INT) AS user_id,
COLUMNS[1] AS username, CAST(COLUMNS[2] AS TIMESTAMP) AS registration_date
FROM `users.csv1`;
You need to select particular columns instead of using SELECT * for performance reasons. Drill reads CSV, TSV, and PSV files into a list of VARCHARS, rather than individual columns.
If your text files have headers, you can enable extractHeader and select particular columns by name. For example:
CREATE TABLE parquet_users AS SELECT CAST(user_id AS INT) AS user_id,
username, CAST(registration_date AS TIMESTAMP) AS registration_date
FROM `users.csv1`;
Cast Data
You can also improve performance by casting the VARCHAR data in a text file to INT, FLOAT, DATETIME, and so on when you read the data from a text file. Drill performs better reading fixed-width than reading VARCHAR data.
Text files that include empty strings might produce unacceptable results. Common ways to deal with empty strings are:
- Set the drill.exec.functions.cast_empty_string_to_null SESSION/SYSTEM option to true.
-
Use a case statement to cast empty strings to values you want. For example, create a Parquet table named test from a CSV file named test.csv, and cast empty strings in the CSV to null in any column the empty string appears:
CREATE TABLE test AS SELECT case when COLUMNS[0] = '' then CAST(NULL AS INTEGER) else CAST(COLUMNS[0] AS INTEGER) end AS c1, case when COLUMNS[1] = '' then CAST(NULL AS VARCHAR(20)) else CAST(COLUMNS[1] AS VARCHAR(20)) end AS c2, case when COLUMNS[2] = '' then CAST(NULL AS DOUBLE) else CAST(COLUMNS[2] AS DOUBLE) end AS c3, case when COLUMNS[3] = '' then CAST(NULL AS DATE) else CAST(COLUMNS[3] AS DATE) end AS c4, case when COLUMNS[4] = '' then CAST(NULL AS VARCHAR(20)) else CAST(COLUMNS[4] AS VARCHAR(20)) end AS c5 FROM `test.csv`;
Use a Distributed File System
Using a distributed file system, such as HDFS, instead of a local file system to query files improves performance because Drill attempts to split files on block boundaries.
Configuring Drill to Read Text Files
In the storage plugin configuration, you set the attributes that affect how Drill reads CSV, TSV, PSV (comma-, tab-, pipe-separated) files:
- comment
- escape
- delimiter
- quote
- skipFirstLine
- extractHeader
Set the sys.options property setting exec.storage.enable_new_text_reader to true (the default) before attempting to use these attributes.
Using Quotation Marks
CSV files typically enclose text fields in double quotation marks, and Drill treats the double quotation mark in CSV files as a special character accordingly. By default, Drill treats double quotation marks as a special character in TSV files also. If you want Drill not to treat double quotation marks as a special character, configure the storage plugin to set the quote attribute to the unicode null "\u0000". For example:
. . .
"tsv": {
"type": "text",
"extensions": [
"tsv"
],
"quote": "\u0000", <-- set this to null
"delimiter": "\t"
},
. . .
As mentioned previously, set the sys.options property setting exec.storage.enable_new_text_reader to true (the default).
**Examples of Querying Text Files **
The examples in this section show the results of querying CSV files that use and do not use a header, include comments, and use an escape character:
Not Using a Header in a File
"csv": {
"type": "text",
"extensions": [
"csv2"
],
"skipFirstLine": true,
"delimiter": ","
},
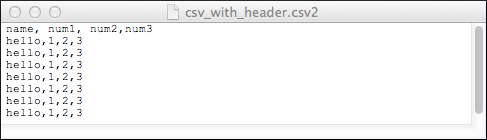
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/tmp/csv_with_header.csv2`;
|------------------------|
| columns |
|------------------------|
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
|------------------------|
7 rows selected (0.112 seconds)
Using a Header in a File
"csv": {
"type": "text",
"extensions": [
"csv2"
],
"skipFirstLine": false,
"extractHeader": true,
"delimiter": ","
},
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/tmp/csv_with_header.csv2`;
|-------|------|------|------|
| name | num1 | num2 | num3 |
|-------|------|------|------|
| hello | 1 | 2 | 3 |
| hello | 1 | 2 | 3 |
| hello | 1 | 2 | 3 |
| hello | 1 | 2 | 3 |
| hello | 1 | 2 | 3 |
| hello | 1 | 2 | 3 |
| hello | 1 | 2 | 3 |
|-------|------|------|------|
7 rows selected (0.12 seconds)
File with no Header
"csv": {
"type": "text",
"extensions": [
"csv"
],
"skipFirstLine": false,
"extractHeader": false,
"delimiter": ","
},
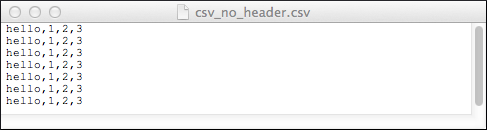
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/tmp/csv_no_header.csv`;
|------------------------|
| columns |
|------------------------|
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
|------------------------|
7 rows selected (0.112 seconds)
Escaping a Character in a File
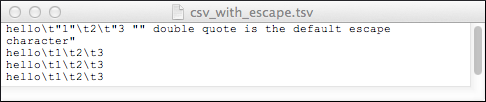
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/tmp/csv_with_escape.csv`;
|------------------------------------------------------------------------|
| columns |
|------------------------------------------------------------------------|
| ["hello","1","2","3 \" double quote is the default escape character"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
|------------------------------------------------------------------------|
7 rows selected (0.104 seconds)
Adding Comments to a File
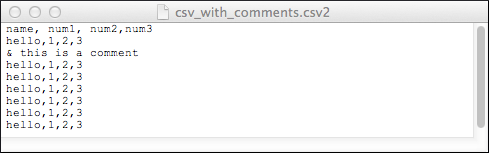
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/tmp/csv_with_comments.csv2`;
|------------------------|
| columns |
|------------------------|
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
| ["hello","1","2","3"] |
|------------------------|
7 rows selected (0.111 seconds)
Strategies for Using Attributes
The attributes, such as skipFirstLine, apply to all workspaces defined in a storage plugin. A typical use case defines separate storage plugins for different root directories to query the files stored below the directory. An alternative use case defines multiple formats within the same storage plugin and names target files using different extensions to match the formats.
You can deal with a mix of text files with and without headers either by creating two separate format plugins or by creating two format plugins within the same storage plugin. The former approach is typically easier than the latter.
Creating Two Separate Storage Plugin Configurations
A storage plugin configuration defines a root directory that Drill targets. You can use a different configuration for each root directory that sets attributes to match the files stored below that directory. All files can use the same extension, such as .csv, as shown in the following example:
Storage Plugin A
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
. . .
Storage Plugin B
"csv": {
"type": "text",
"extensions": [
"csv"
],
"comment": "&",
"skipFirstLine": false,
"extractHeader": true,
"delimiter": ","
},
Creating One Storage Plugin Configuration to Handle Multiple Formats
You can use a different extension for files with and without a header, and use a storage plugin that looks something like the following example. This method requires renaming some files to use the csv2 extension.
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
"csv_with_header": {
"type": "text",
"extensions": [
"csv2"
],
"comment": "&",
"skipFirstLine": false,
"extractHeader": true,
"delimiter": ","
},
Converting a CSV file to Apache Parquet
A common use case when working with Hadoop is to store and query text files, such as CSV and TSV. To get better performance and efficient storage, you convert these files into Parquet. You can use code to achieve this, as you can see in the ConvertUtils sample/test class. A simpler way to convert these text files to Parquet is to query the text files using Drill, and save the result to Parquet files.
How to Convert CSV to Parquet
This example uses the Passenger Dataset from SFO Air Traffic Statistics.
-
Execute a basic query:
SELECT * FROM dfs.`/opendata/Passenger/SFO_Passenger_Data/MonthlyPassengerData_200507_to_201503.csv` LIMIT 5; ["200507","ATA Airlines","TZ","ATA Airlines","TZ","Domestic","US","Deplaned","Low Fare","Terminal 1","B","27271\r"] ... ...By default Drill processes each line as an array of columns, all values being a simple string. To do some operations with these values (projection or conditional query) you must convert the strings to proper types.
-
Use the column index, and cast the value to the proper type.
SELECT columns[0] as `DATE`, columns[1] as `AIRLINE`, CAST(columns[11] AS DOUBLE) as `PASSENGER_COUNT` FROM dfs.`/opendata/Passenger/SFO_Passenger_Data/*.csv` WHERE CAST(columns[11] AS DOUBLE) < 5 ; |---------|-----------------------------------|------------------| | DATE | AIRLINE | PASSENGER_COUNT | |---------|-----------------------------------|------------------| | 200610 | United Airlines - Pre 07/01/2013 | 2.0 | ... ... -
Create Parquet files.
ALTER SESSION SET `store.format`='parquet'; CREATE TABLE dfs.tmp.`/stats/airport_data/` AS SELECT CAST(SUBSTR(columns[0],1,4) AS INT) `YEAR`, CAST(SUBSTR(columns[0],5,2) AS INT) `MONTH`, columns[1] as `AIRLINE`, columns[2] as `IATA_CODE`, columns[3] as `AIRLINE_2`, columns[4] as `IATA_CODE_2`, columns[5] as `GEO_SUMMARY`, columns[6] as `GEO_REGION`, columns[7] as `ACTIVITY_CODE`, columns[8] as `PRICE_CODE`, columns[9] as `TERMINAL`, columns[10] as `BOARDING_AREA`, CAST(columns[11] AS DOUBLE) as `PASSENGER_COUNT` FROM dfs.`/opendata/Passenger/SFO_Passenger_Data/*.csv` -
Use the Parquet file in any of your Hadoop processes, or use Drill to query the file as follows:
SELECT * FROM dfs.tmp.`/stats/airport_data/*`