
Configuring Tibco Spotfire Server with Drill
This document describes how to configure Tibco Spotfire Server (TSS) to integrate with Apache Drill and explore multiple data formats instantly on Hadoop. Users can combine these powerful platforms to rapidly gain analytical access to a wide variety of data types.
Complete the following steps to configure and use Apache Drill with TSS:
- Install the Drill JDBC driver with TSS.
- Configure the Drill Data Source Template in TSS with the TSS configuration tool.
- Configure Drill data sources with Tibco Spotfire Desktop and Information Designer.
- Query and analyze various data formats with Tibco Spotfire and Drill.
Step 1: Install and Configure the Drill JDBC Driver
Drill provides standard JDBC connectivity, making it easy to integrate data exploration capabilities on complex, schema-less data sets. Tibco Spotfire Server (TSS) requires Drill 1.0 or later, which incudes the JDBC driver. The JDBC driver is bundled with the Drill configuration files, and it is recommended that you use the JDBC driver that is shipped with the specific Drill version.
For general instructions to install the Drill JDBC driver, see Using JDBC. Complete the following steps to install and configure the JDBC driver for TSS:
-
Locate the JDBC driver in the Drill installation directory:
<drill-home>/jars/jdbc-driver/drill-jdbc-all-<drill-version>.jarFor example, on a MapR cluster:/opt/mapr/drill/drill-1.0.0/jars/jdbc-driver/drill-jdbc-all-1.0.0-SNAPSHOT.jar -
Locate the TSS library directory and copy the JDBC driver file to that directory:
<TSS-home-directory>/tomcat/libFor example, on a Linux server:/usr/local/bin/tibco/tss/6.0.3/tomcat/libFor example, on a Windows server:C:\Program Files\apache-tomcat\lib - Restart TSS to load the JDBC driver.
- Verify that the TSS system can resolve the hostnames of the ZooKeeper nodes for the Drill cluster. You can do this by validating that DNS is properly configured for the TSS system and all the ZooKeeper nodes. Alternatively, you can add the hostnames and IP addresses of the ZooKeeper nodes to the TSS system hosts file.
For Linux systems, the hosts file is located here:
/etc/hostsFor Windows systems, the hosts file is located here:%WINDIR%\system32\drivers\etc\hosts
Step 2: Configure the Drill Data Source Template in TSS
The Drill Data Source template can now be configured with the TSS Configuration Tool. The Windows-based TSS Configuration Tool is recommended. If TSS is installed on a Linux system, you also need to install TSS on a small Windows-based system so you can utilize the Configuration Tool. In this case, it is also recommended that you install the Drill JDBC driver on the TSS Windows system.
- Click Start > All Programs > TIBCO Spotfire Server > Configure TIBCO Spotfire Server.
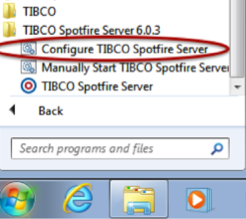
- Enter the Configuration Tool password that was specified when TSS was initially installed.
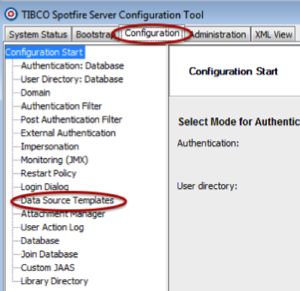
- Once the Configuration Tool has connected to TSS, click the Configuration tab, then Data Source Templates.
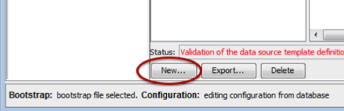
- In the Data Source Templates window, click the New button at the bottom of the window.
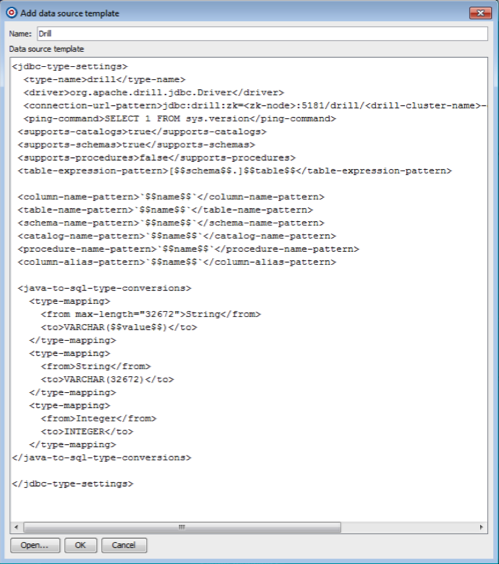
- Provide a name for the data source template, then copy the following XML template into the Data Source Template box. When complete, click OK.
- The new entry will now be available in the data source template. Check the box next to the new entry, then click Save Configuration.
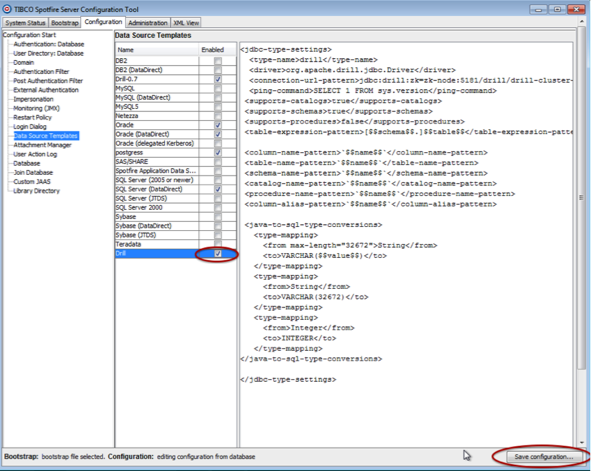
- Select Database as the destination and click Next.
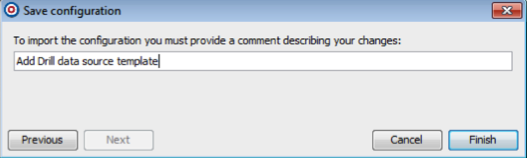
- Add a comment to the updated configuration and click Finish.
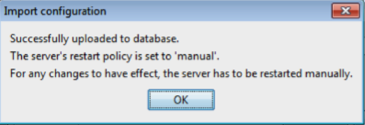
- A response window is displayed to state that the configuration was successfully uploaded to TSS. Click OK.
- Restart TSS to enable it to use the Drill data source template.
XML Template
Make sure that you enter the correct ZooKeeper node name instead of <zk-node>, as well as the correct Drill cluster name instead of <drill-cluster-name> in the example below. This is just a template that will appear whenever a data source is configured. The hostnames of ZooKeeper nodes and the Drill cluster name can be found in the $DRILL_HOME/conf/drill-override.conf file on any of the Drill nodes in the cluster.
<jdbc-type-settings>
<type-name>drill</type-name>
<driver>org.apache.drill.jdbc.Driver</driver>
<connection-url-pattern>jdbc:drill:zk=<zk-node>:5181/drill/<drill-cluster-name>-drillbits</connection-url-pattern>
<ping-command>SELECT 1 FROM sys.version</ping-command>
<supports-catalogs>true</supports-catalogs>
<supports-schemas>true</supports-schemas>
<supports-procedures>false</supports-procedures>
<table-expression-pattern>[$$schema$$.]$$table$$</table-expression-pattern>
<column-name-pattern>`$$name$$`</column-name-pattern>
<table-name-pattern>`$$name$$`</table-name-pattern>
<schema-name-pattern>`$$name$$`</schema-name-pattern>
<catalog-name-pattern>`$$name$$`</catalog-name-pattern>
<procedure-name-pattern>`$$name$$`</procedure-name-pattern>
<column-alias-pattern>`$$name$$`</column-alias-pattern>
<java-to-sql-type-conversions>
<type-mapping>
<from max-length="32672">String</from>
<to>VARCHAR($$value$$)</to>
</type-mapping>
<type-mapping>
<from>String</from>
<to>VARCHAR(32672)</to>
</type-mapping>
<type-mapping>
<from>Integer</from>
<to>INTEGER</to>
</type-mapping>
</java-to-sql-type-conversions>
</jdbc-type-settings>
Step 3: Configure Drill Data Sources with Tibco Spotfire Desktop
To configure Drill data sources in TSS, you need to use the Tibco Spotfire Desktop client.
- Open Tibco Spotfire Desktop.
- Log into TSS.
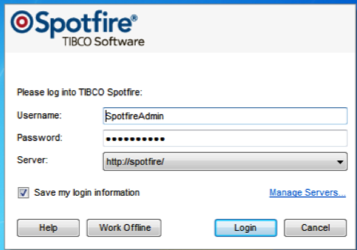
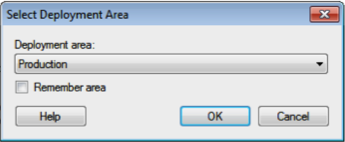
- Select the deployment area in TSS to be used.
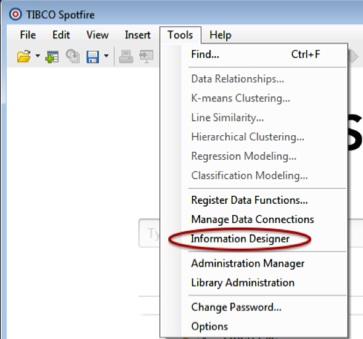
- Click Tools > Information Designer.
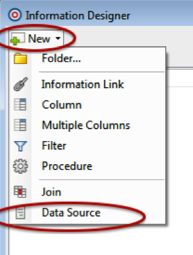
- In the Information Designer, click New > Data Source.
- In the Data Source window, enter the name for the data source. Select the Drill Data Source template created in Step 2 as the type. Update the connection URL with the correct hostname of the ZooKeeper node(s) and the Drill cluster name. Note: The Zookeeper node(s) hostname(s) and Drill cluster name can be found in the
$DRILL_HOME/conf/drill-override.conffile on any of the Drill nodes in the cluster. Enter the username and password used to connect to Drill. When completed, click Save.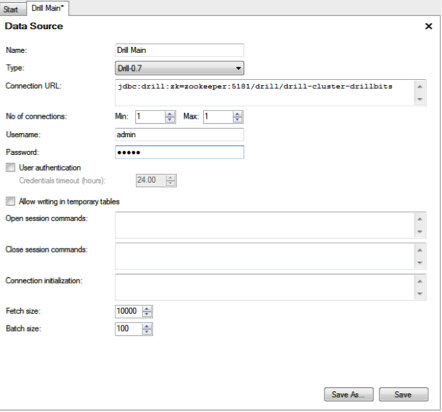
- In the Save As window, verify the name and the folder where you want to save the new data source in TSS. Click Save when done. TSS will now validate the information and save the new data source in TSS.
- When the data source is saved, it will appear in the Data Sources tab, and you will be able to navigate the schema.
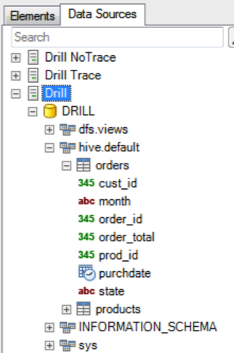
Step 4: Query and Analyze the Data
After the Drill data source has been configured in the Information Designer, the information elements can be defined.
- In this example all the columns of a Hive table have been defined, using the Drill data source, and added to an information link.
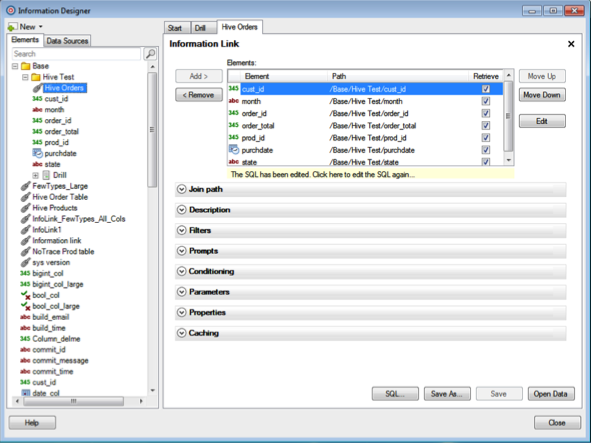
- The SQL syntax to retrieve the data can be validated by clicking the SQL button. Many other operations can be performed in Information Link, including joins, filters, and so on. See the Tibco Spotfire documentation for details.
- You can now import the data of this table into TSS by clicking the Open Data button.
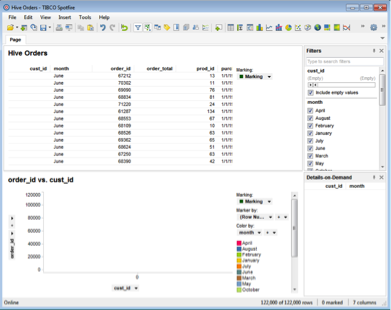 The data is now available in Tibco Spotfire Desktop to create various reports and tables as needed, and to be shared. For more information about creating charts, tables and reports, see the Tibco Spotfire documentation.
The data is now available in Tibco Spotfire Desktop to create various reports and tables as needed, and to be shared. For more information about creating charts, tables and reports, see the Tibco Spotfire documentation.