
Core Modules
The following image represents components within each Drillbit:
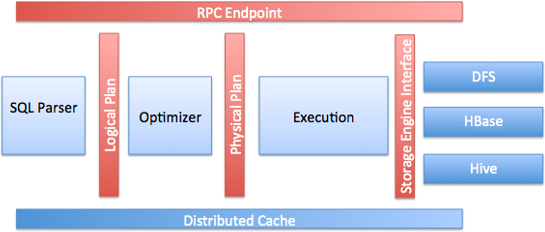
The following list describes the key components of a Drillbit:
-
RPC endpoint: Drill exposes a low overhead protobuf-based RPC protocol to communicate with the clients. Additionally, C++ and Java API layers are also available for client applications to interact with Drill. Clients can communicate with a specific Drillbit directly or go through a ZooKeeper quorum to discover the available Drillbits before submitting queries. It is recommended that the clients always go through ZooKeeper to shield clients from the intricacies of cluster management, such as the addition or removal of nodes.
- SQL parser: Drill uses Calcite, the open source SQL parser framework, to parse incoming queries. The output of the parser component is a language agnostic, computer-friendly logical plan that represents the query.
- Storage plugin interface: Drill serves as a query layer on top of several data sources. Storage plugins in Drill represent the abstractions that Drill uses to interact with the data sources. Storage plugins provide Drill with the following information:
- Metadata available in the source
- Interfaces for Drill to read from and write to data sources
- Location of data and a set of optimization rules to help with efficient and fast execution of Drill queries on a specific data source
In the context of Hadoop, Drill provides storage plugins for distributed files and HBase. Drill also integrates with Hive using a storage plugin.
When users query files and HBase with Drill, they can do it directly or go through Hive if they have metadata defined there. Drill integration with Hive is only for metadata. Drill does not invoke the Hive execution engine for any requests.