
Performance
Drill is designed from the ground up for high performance on large datasets. The following core elements of Drill processing are responsible for Drill’s performance:
Distributed engine
Drill provides a powerful distributed execution engine for processing queries. Users can submit requests to any node in the cluster. You can add new nodes to the cluster to scale for larger volumes of data to support more users or improve performance.
Columnar execution
Drill optimizes for both columnar storage and execution by using an in-memory data model that is hierarchical and columnar. When working with data stored in columnar formats such as Parquet, Drill avoids disk access for columns that are not involved in a query. Drill’s execution layer also performs SQL processing directly on columnar data without row materialization. The combination of optimizations for columnar storage and direct columnar execution significantly lowers memory footprints and provides faster execution of BI and analytic types of workloads.
Vectorization
Rather than operating on single values from a single table record at one time, vectorization in Drill allows the CPU to operate on vectors, referred to as a record batches. A record batch has arrays of values from many different records. The technical basis for efficiency of vectorized processing is modern chip technology with deep-pipelined CPU designs. Keeping all pipelines full to achieve efficiency near peak performance is impossible to achieve in traditional database engines, primarily due to code complexity.
Runtime compilation
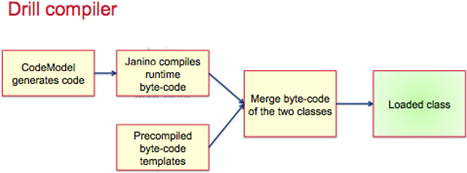
Runtime compilation enables faster execution than interpreted execution. Drill generates highly efficient custom code for every single query. The following image shows the Drill compilation/code generation process:
Optimistic and pipelined query execution
Using an optimistic execution model to process queries, Drill assumes that failures are infrequent within the short span of a query. Drill does not spend time creating boundaries or checkpoints to minimize recovery time. In the instance of a single query failure, the query is rerun. Drill execution uses a pipeline model where all tasks are scheduled at once. The query execution happens in- memory as much as possible to move data through task pipelines, persisting to disk only if there is memory overflow.