
第三课: 查询复杂数据类型
目标
本课重点介绍在 self-describing 数据和复杂数据类型上运用函数和运算符的查询。Drill 通过直观的 SQL 扩展来处理此类数据,并通过专用架构为复杂数据类型提供高查询性能。
本课中的查询示例
之前已经对含有关系数据的表和文件运行了 ANSI SQL 查询,针对复杂数据类型再做一些示例查询:
- 在单个 SELECT 语句中访问文件的目录和子目录。
- 轻松访问 JSON 文件中复杂数据的方法。
- 通过 repeat_count 函数来聚合数组中的值。
查询分区目录
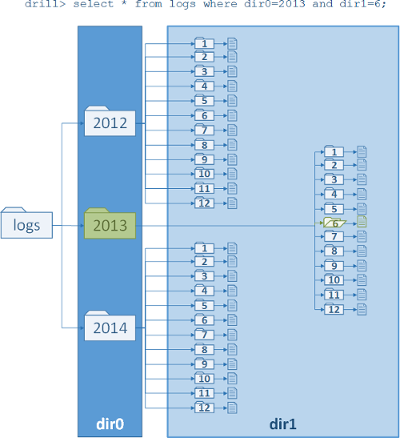
您可以在 Drill 中使用特殊变量来引用文件路径中的子目录:
- dir0
- dir1
- …
请注意,这些变量是根据文件系统的分区动态确定的。不需要预先定义存在哪些分区。以下是其工作原理的示例:
将工作区设置为 dfs.logs:
0: jdbc:drill:> use dfs.logs;
|-------|---------------------------------------|
| ok | summary |
|-------|---------------------------------------|
| true | Default schema changed to [dfs.logs] |
|-------|---------------------------------------|
1 row selected
查询特定年份的日志数据:
0: jdbc:drill:> select * from logs where dir0='2013' limit 10;
|-------|-------|-----------|-------------|-----------|----------|---------|--------|----------|-----------|----------|-------------|
| dir0 | dir1 | trans_id | date | time | cust_id | device | state | camp_id | keywords | prod_id | purch_flag |
|-------|-------|-----------|-------------|-----------|----------|---------|--------|----------|-----------|----------|-------------|
| 2013 | 8 | 12104 | 08/29/2013 | 09:34:37 | 962 | IOS5 | ma | 3 | milhouse | 17 | false |
| 2013 | 8 | 12132 | 08/23/2013 | 01:11:25 | 4 | IOS7 | mi | 11 | hi | 439 | false |
| 2013 | 8 | 12177 | 08/14/2013 | 13:48:50 | 23 | AOS4.2 | il | 14 | give | 382 | false |
| 2013 | 8 | 12180 | 08/03/2013 | 20:48:45 | 1509 | IOS7 | ca | 0 | i'm | 340 | false |
| 2013 | 8 | 12187 | 08/16/2013 | 10:28:07 | 0 | IOS5 | ny | 16 | clicking | 11 | false |
| 2013 | 8 | 12190 | 08/10/2013 | 14:16:50 | 9 | IOS5 | va | 3 | a | 495 | false |
| 2013 | 8 | 12200 | 08/02/2013 | 20:54:38 | 42219 | IOS5 | ia | 0 | what's | 346 | false |
| 2013 | 8 | 12210 | 08/05/2013 | 20:12:24 | 8073 | IOS5 | sc | 5 | if | 33 | false |
| 2013 | 8 | 12235 | 08/28/2013 | 07:49:45 | 595 | IOS5 | tx | 2 | that | 51 | false |
| 2013 | 8 | 12239 | 08/13/2013 | 03:24:31 | 2 | IOS5 | or | 6 | haw-haw | 40 | false |
|-------|-------|-----------|-------------|-----------|----------|---------|--------|----------|-----------|----------|-------------|
10 rows selected
此查询将文件限制在名为 2013 的子目录中。变量 dir0 指的是从日志目录向下的第一级,dir1 到下一级,依此类推。所以这个查询返回了 2013 年文件夹中的前 10 个文件。
在查询中使用多个条件进一步限制结果:
此查询返回 2013 年 8 月通过 IOS5 设备有过购买记录的客户 ID 数据。
0: jdbc:drill:> select dir0 as yr, dir1 as mth, cust_id from logs
where dir0='2013' and dir1='8' and device='IOS5' and purch_flag='true'
order by `date`;
|-------|------|----------|
| yr | mth | cust_id |
|-------|------|----------|
| 2013 | 8 | 4 |
| 2013 | 8 | 521 |
| 2013 | 8 | 1 |
| 2013 | 8 | 2 |
...
返回特定年份中每个客户每月的复购次数:
0: jdbc:drill:> select cust_id, dir1 month_no, count(*) month_count from logs
where dir0=2014 group by cust_id, dir1 order by cust_id, month_no limit 10;
|----------|-----------|--------------|
| cust_id | month_no | month_count |
|----------|-----------|--------------|
| 0 | 1 | 143 |
| 0 | 2 | 118 |
| 0 | 3 | 117 |
| 0 | 4 | 115 |
| 0 | 5 | 137 |
| 0 | 6 | 117 |
| 0 | 7 | 142 |
| 0 | 8 | 19 |
| 1 | 1 | 66 |
| 1 | 2 | 59 |
|----------|-----------|--------------|
10 rows selected
此查询指定在2014年中根据客户 ID 和月份使用聚合函数进行分组。
查询复杂数据
Drill 提供了一些专门的操作符和函数,无需转换即可用来分析嵌套数据。如果用户熟悉 JSON,就可以轻松掌握这些扩展功能。
将工作区设置为 dfs.clicks:
0: jdbc:drill:> use dfs.clicks;
|-------|-----------------------------------------|
| ok | summary |
|-------|-----------------------------------------|
| true | Default schema changed to [dfs.clicks] |
|-------|-----------------------------------------|
1 row selected
探索点击流数据:
请注意,user_info 和 trans_info 列包含嵌套数据:数组和嵌套数组。以下查询展示了如何访问此类复杂数据。
0: jdbc:drill:> select * from `clicks/clicks.json` limit 5;
|-----------|-------------|-----------|---------------------------------------------------|---------------------------------------------------------------------------|
| trans_id | date | time | user_info | trans_info |
|-----------|-------------|-----------|---------------------------------------------------|---------------------------------------------------------------------------|
| 31920 | 2014-04-26 | 12:17:12 | {"cust_id":22526,"device":"IOS5","state":"il"} | {"prod_id":[174,2],"purch_flag":"false"} |
| 31026 | 2014-04-20 | 13:50:29 | {"cust_id":16368,"device":"AOS4.2","state":"nc"} | {"prod_id":[],"purch_flag":"false"} |
| 33848 | 2014-04-10 | 04:44:42 | {"cust_id":21449,"device":"IOS6","state":"oh"} | {"prod_id":[582],"purch_flag":"false"} |
| 32383 | 2014-04-18 | 06:27:47 | {"cust_id":20323,"device":"IOS5","state":"oh"} | {"prod_id":[710,47],"purch_flag":"false"} |
| 32359 | 2014-04-19 | 23:13:25 | {"cust_id":15360,"device":"IOS5","state":"ca"} | {"prod_id":[0,8,170,173,1,124,46,764,30,711,0,3,25],"purch_flag":"true"} |
|-----------|-------------|-----------|---------------------------------------------------|---------------------------------------------------------------------------|
5 rows selected
解析 user_info 列:
0: jdbc:drill:> select t.user_info.cust_id as custid, t.user_info.device as device,
t.user_info.state as state
from `clicks/clicks.json` t limit 5;
|---------|---------|--------|
| custid | device | state |
|---------|---------|--------|
| 22526 | IOS5 | il |
| 16368 | AOS4.2 | nc |
| 21449 | IOS6 | oh |
| 20323 | IOS5 | oh |
| 15360 | IOS5 | ca |
|---------|---------|--------|
5 rows selected (0.171 seconds)
此查询使用简单的 table.column.column 表示法来提取嵌套列数据。例如:
t.user_info.cust_id
其中 t 是查询中提供的表别名,user_info 是顶级列名,cust_id 是嵌套列名。
表别名是必需的;否则,“user_info” 之类的列名会被 SQL 解析器解析为表名。
解析 trans_info 列:
0: jdbc:drill:> select t.trans_info.prod_id as prodid, t.trans_info.purch_flag as
purchased
from `clicks/clicks.json` t limit 5;
|-------------------------------------------|------------|
| prodid | purchased |
|-------------------------------------------|------------|
| [174,2] | false |
| [] | false |
| [582] | false |
| [710,47] | false |
| [0,8,170,173,1,124,46,764,30,711,0,3,25] | true |
|-------------------------------------------|------------|
5 rows selected
请注意,此结果表明 prod_id 列包含一组 ID(每行一个或多个产品 ID 值,以逗号分隔)。下一步将展示如何访问此类数据。
查询数组
现在使用 [n] 表示法,其中 n 是数组中值的位置,从第一个值的位置 0(不是 1)开始。用户可以使用此表示法针对嵌套数组数据进行的查询。
比如:
trans_info.prod_id[0]
指嵌套的 prod_id 列中的第一个值和
trans_info.prod_id[20]
指到第 21 个值,假设存在第21个值。
查找每笔交易中搜索的第一个产品:
0: jdbc:drill:> select t.trans_id, t.trans_info.prod_id[0] from `clicks/clicks.json` t limit 5;
|------------|------------|
| trans_id | EXPR$1 |
|------------|------------|
| 31920 | 174 |
| 31026 | null |
| 33848 | 582 |
| 32383 | 710 |
| 32359 | 0 |
|------------|------------|
5 rows selected
哪些交易客户搜索了至少 21 种产品?
0: jdbc:drill:> select t.trans_id, t.trans_info.prod_id[20]
from `clicks/clicks.json` t
where t.trans_info.prod_id[20] is not null
order by trans_id limit 5;
|------------|------------|
| trans_id | EXPR$1 |
|------------|------------|
| 10328 | 0 |
| 10380 | 23 |
| 10701 | 1 |
| 11100 | 0 |
| 11219 | 46 |
|------------|------------|
5 rows selected
对于在数组的第 21 个位置包含非空产品 ID 的交易记录,此查询将返回此交易的交易 ID 和产品 ID。
返回特定产品范围的点击次数:
0: jdbc:drill:> select * from (select t.trans_id, t.trans_info.prod_id[0] as prodid,
t.trans_info.purch_flag as purchased
from `clicks/clicks.json` t) sq
where sq.prodid between 700 and 750 and sq.purchased='true'
order by sq.prodid;
|------------|------------|------------|
| trans_id | prodid | purchased |
|------------|------------|------------|
| 21886 | 704 | true |
| 20674 | 708 | true |
| 22158 | 709 | true |
| 34089 | 714 | true |
| 22545 | 714 | true |
| 37500 | 717 | true |
| 36595 | 718 | true |
...
此查询假定数组具有某种意义(即它是已购买产品的有序表而不是随机列表)。
对数组执行操作
对会话中成功的点击转化和搜索的产品数量进行排名:
0: jdbc:drill:> select t.trans_id, t.`date` as session_date, t.user_info.cust_id as
cust_id, t.user_info.device as device, repeated_count(t.trans_info.prod_id) as
prod_count, t.trans_info.purch_flag as purch_flag
from `clicks/clicks.json` t
where t.trans_info.purch_flag = 'true' order by prod_count desc;
|------------|--------------|------------|------------|------------|------------|
| trans_id | session_date | cust_id | device | prod_count | purch_flag |
|------------|--------------|------------|------------|------------|------------|
| 37426 | 2014-04-06 | 18709 | IOS5 | 34 | true |
| 31589 | 2014-04-16 | 18576 | IOS6 | 31 | true |
| 11600 | 2014-04-07 | 4260 | AOS4.2 | 28 | true |
| 35074 | 2014-04-03 | 16697 | AOS4.3 | 27 | true |
| 17192 | 2014-04-22 | 2501 | AOS4.2 | 26 | true |
...
此查询使用 SQL 扩展,通过 repeat_count 函数来获取数组值的聚合统计。该查询返回每个会话中搜索的产品数量,按降序排列。仅统计转化为购买的点击次数。
将结果集存储在表中方便重用和分析
为了便于对此结果集进行额外分析,用户可以根据查询结果快捷地创建 Drill 表。
继续使用 dfs.clicks 工作区:
0: jdbc:drill:> use dfs.clicks;
|-------|-----------------------------------------|
| ok | summary |
|-------|-----------------------------------------|
| true | Default schema changed to [dfs.clicks] |
|-------|-----------------------------------------|
1 row selected (1.61 seconds)
返回高价值客户的产品搜索:
0: jdbc:drill:> select o.cust_id, o.order_total, t.trans_info.prod_id[0] as prod_id
from
hive.orders as o
join `clicks/clicks.json` t
on o.cust_id=t.user_info.cust_id
where o.order_total > (select avg(inord.order_total)
from hive.orders inord
where inord.state = o.state);
|----------|--------------|----------|
| cust_id | order_total | prod_id |
|----------|--------------|----------|
| 1328 | 73 | 26 |
| 1328 | 146 | 26 |
| 1328 | 56 | 26 |
| 1328 | 91 | 26 |
| 1328 | 74 | 26 |
...
|----------|--------------|----------|
107,482 rows selected (14.863 seconds)
此查询返回一个产品列表,这些产品被客户搜索的产品的交易额高于其所在州的平均水平。
保存上一个查询的结果:
0: jdbc:drill:> create table product_search as select o.cust_id, o.order_total, t.trans_info.prod_id[0] as prod_id
from
hive.orders as o
join `clicks/clicks.json` t
on o.cust_id=t.user_info.cust_id
where o.order_total > (select avg(inord.order_total)
from hive.orders inord
where inord.state = o.state);
|-----------|----------------------------|
| Fragment | Number of records written |
|-----------|----------------------------|
| 0_0 | 107482 |
|-----------|----------------------------|
1 row selected (3.488 seconds)
此示例使用 CTAS 语句将上一个查询的结果创建为表。该表包含查询返回的所有行 (107,482),并以存储插件指定的格式(本例中为 Parquet 格式)存储。用户可以创建以 csv、parquet 和 json 格式存储的表。
查询新表以验证行数:
此示例仅通过验证表中的行数来检查 CTAS 语句是否有效。
0: jdbc:drill:> select count(*) from product_search;
|---------|
| EXPR$0 |
|---------|
| 107482 |
|---------|
1 row selected (0.155 seconds)
找到表的存储文件:
[root@maprdemo product_search]# cd /mapr/demo.mapr.com/data/nested/product_search
[root@maprdemo product_search]# ls -la
total 451
drwxr-xr-x. 2 mapr mapr 1 Sep 15 13:41 .
drwxr-xr-x. 4 root root 2 Sep 15 13:41 ..
-rwxr-xr-x. 1 mapr mapr 460715 Sep 15 13:41 0_0_0.parquet
请注意,该表存储在名为 “0_0_0.parquet” 的文件中。这个文件存储在 dfs.clicks 工作区定义的位置:
"location": "http://demo.mapr.com/data/nested"
有一个子目录与您创建的表同名。
下一步
完成教程并 总结。