
Lesson 3: Run Queries on Complex Data Types
Goal
This lesson focuses on queries that exercise functions and operators on self- describing data and complex data types. Drill offers intuitive SQL extensions to work with such data and offers high query performance with an architecture built from the ground up for complex data.
Queries in This Lesson
Now that you have run ANSI SQL queries against different tables and files with relational data, you can try some examples including complex types.
- Access directories and subdirectories of files in a single SELECT statement.
- Demonstrate simple ways to access complex data in JSON files.
- Demonstrate the repeated_count function to aggregate values in an array.
Query Partitioned Directories
You can use special variables in Drill to refer to subdirectories in your workspace path:
- dir0
- dir1
- …
Note that these variables are dynamically determined based on the partitioning of the file system. No up-front definitions are required on what partitions exist. Here is a visual example of how this works:
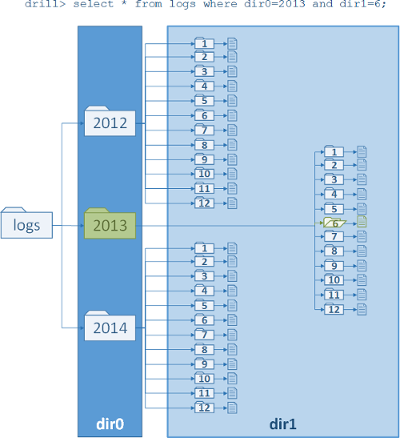
Set workspace to dfs.logs:
0: jdbc:drill:> use dfs.logs;
|-------|---------------------------------------|
| ok | summary |
|-------|---------------------------------------|
| true | Default schema changed to [dfs.logs] |
|-------|---------------------------------------|
1 row selected
Query logs data for a specific year:
0: jdbc:drill:> select * from logs where dir0='2013' limit 10;
|-------|-------|-----------|-------------|-----------|----------|---------|--------|----------|-----------|----------|-------------|
| dir0 | dir1 | trans_id | date | time | cust_id | device | state | camp_id | keywords | prod_id | purch_flag |
|-------|-------|-----------|-------------|-----------|----------|---------|--------|----------|-----------|----------|-------------|
| 2013 | 8 | 12104 | 08/29/2013 | 09:34:37 | 962 | IOS5 | ma | 3 | milhouse | 17 | false |
| 2013 | 8 | 12132 | 08/23/2013 | 01:11:25 | 4 | IOS7 | mi | 11 | hi | 439 | false |
| 2013 | 8 | 12177 | 08/14/2013 | 13:48:50 | 23 | AOS4.2 | il | 14 | give | 382 | false |
| 2013 | 8 | 12180 | 08/03/2013 | 20:48:45 | 1509 | IOS7 | ca | 0 | i'm | 340 | false |
| 2013 | 8 | 12187 | 08/16/2013 | 10:28:07 | 0 | IOS5 | ny | 16 | clicking | 11 | false |
| 2013 | 8 | 12190 | 08/10/2013 | 14:16:50 | 9 | IOS5 | va | 3 | a | 495 | false |
| 2013 | 8 | 12200 | 08/02/2013 | 20:54:38 | 42219 | IOS5 | ia | 0 | what's | 346 | false |
| 2013 | 8 | 12210 | 08/05/2013 | 20:12:24 | 8073 | IOS5 | sc | 5 | if | 33 | false |
| 2013 | 8 | 12235 | 08/28/2013 | 07:49:45 | 595 | IOS5 | tx | 2 | that | 51 | false |
| 2013 | 8 | 12239 | 08/13/2013 | 03:24:31 | 2 | IOS5 | or | 6 | haw-haw | 40 | false |
|-------|-------|-----------|-------------|-----------|----------|---------|--------|----------|-----------|----------|-------------|
10 rows selected
This query constrains files inside the subdirectory named 2013. The variable dir0 refers to the first level down from logs, dir1 to the next level, and so on. So this query returned 10 of the rows for February 2013.
Further constrain the results using multiple predicates in the query:
This query returns a list of customer IDs for people who made a purchase via an IOS5 device in August 2013.
0: jdbc:drill:> select dir0 as yr, dir1 as mth, cust_id from logs
where dir0='2013' and dir1='8' and device='IOS5' and purch_flag='true'
order by `date`;
|-------|------|----------|
| yr | mth | cust_id |
|-------|------|----------|
| 2013 | 8 | 4 |
| 2013 | 8 | 521 |
| 2013 | 8 | 1 |
| 2013 | 8 | 2 |
...
Return monthly counts per customer for a given year:
0: jdbc:drill:> select cust_id, dir1 month_no, count(*) month_count from logs
where dir0=2014 group by cust_id, dir1 order by cust_id, month_no limit 10;
|----------|-----------|--------------|
| cust_id | month_no | month_count |
|----------|-----------|--------------|
| 0 | 1 | 143 |
| 0 | 2 | 118 |
| 0 | 3 | 117 |
| 0 | 4 | 115 |
| 0 | 5 | 137 |
| 0 | 6 | 117 |
| 0 | 7 | 142 |
| 0 | 8 | 19 |
| 1 | 1 | 66 |
| 1 | 2 | 59 |
|----------|-----------|--------------|
10 rows selected
This query groups the aggregate function by customer ID and month for one year: 2014.
Query Complex Data
Drill provides some specialized operators and functions that you can use to analyze nested data natively without transformation. If you are familiar with JavaScript notation, you will already know how some of these extensions work.
Set the workspace to dfs.clicks:
0: jdbc:drill:> use dfs.clicks;
|-------|-----------------------------------------|
| ok | summary |
|-------|-----------------------------------------|
| true | Default schema changed to [dfs.clicks] |
|-------|-----------------------------------------|
1 row selected
Explore clickstream data:
Note that the user_info and trans_info columns contain nested data: arrays and arrays within arrays. The following queries show how to access this complex data.
0: jdbc:drill:> select * from `clicks/clicks.json` limit 5;
|-----------|-------------|-----------|---------------------------------------------------|---------------------------------------------------------------------------|
| trans_id | date | time | user_info | trans_info |
|-----------|-------------|-----------|---------------------------------------------------|---------------------------------------------------------------------------|
| 31920 | 2014-04-26 | 12:17:12 | {"cust_id":22526,"device":"IOS5","state":"il"} | {"prod_id":[174,2],"purch_flag":"false"} |
| 31026 | 2014-04-20 | 13:50:29 | {"cust_id":16368,"device":"AOS4.2","state":"nc"} | {"prod_id":[],"purch_flag":"false"} |
| 33848 | 2014-04-10 | 04:44:42 | {"cust_id":21449,"device":"IOS6","state":"oh"} | {"prod_id":[582],"purch_flag":"false"} |
| 32383 | 2014-04-18 | 06:27:47 | {"cust_id":20323,"device":"IOS5","state":"oh"} | {"prod_id":[710,47],"purch_flag":"false"} |
| 32359 | 2014-04-19 | 23:13:25 | {"cust_id":15360,"device":"IOS5","state":"ca"} | {"prod_id":[0,8,170,173,1,124,46,764,30,711,0,3,25],"purch_flag":"true"} |
|-----------|-------------|-----------|---------------------------------------------------|---------------------------------------------------------------------------|
5 rows selected
Unpack the user_info column:
0: jdbc:drill:> select t.user_info.cust_id as custid, t.user_info.device as device,
t.user_info.state as state
from `clicks/clicks.json` t limit 5;
|---------|---------|--------|
| custid | device | state |
|---------|---------|--------|
| 22526 | IOS5 | il |
| 16368 | AOS4.2 | nc |
| 21449 | IOS6 | oh |
| 20323 | IOS5 | oh |
| 15360 | IOS5 | ca |
|---------|---------|--------|
5 rows selected (0.171 seconds)
This query uses a simple table.column.column notation to extract nested column data. For example:
t.user_info.cust_id
where t is the table alias provided in the query, user_info is a top-level
column name, and cust_id is a nested column name.
The table alias is required; otherwise column names such as user_info are
parsed as table names by the SQL parser.
Unpack the trans_info column:
0: jdbc:drill:> select t.trans_info.prod_id as prodid, t.trans_info.purch_flag as
purchased
from `clicks/clicks.json` t limit 5;
|-------------------------------------------|------------|
| prodid | purchased |
|-------------------------------------------|------------|
| [174,2] | false |
| [] | false |
| [582] | false |
| [710,47] | false |
| [0,8,170,173,1,124,46,764,30,711,0,3,25] | true |
|-------------------------------------------|------------|
5 rows selected
Note that this result reveals that the prod_id column contains an array of IDs (one or more product ID values per row, separated by commas). The next step shows how you to access this kind of data.
Query Arrays
Now use the [n] notation, where n is the position of the value in an array, starting from position 0 (not 1) for the first value. You can use this notation to write interesting queries against nested array data.
For example:
trans_info.prod_id[0]
refers to the first value in the nested prod_id column and
trans_info.prod_id[20]
refers to the 21st value, assuming one exists.
Find the first product that is searched for in each transaction:
0: jdbc:drill:> select t.trans_id, t.trans_info.prod_id[0] from `clicks/clicks.json` t limit 5;
|------------|------------|
| trans_id | EXPR$1 |
|------------|------------|
| 31920 | 174 |
| 31026 | null |
| 33848 | 582 |
| 32383 | 710 |
| 32359 | 0 |
|------------|------------|
5 rows selected
For which transactions did customers search on at least 21 products?
0: jdbc:drill:> select t.trans_id, t.trans_info.prod_id[20]
from `clicks/clicks.json` t
where t.trans_info.prod_id[20] is not null
order by trans_id limit 5;
|------------|------------|
| trans_id | EXPR$1 |
|------------|------------|
| 10328 | 0 |
| 10380 | 23 |
| 10701 | 1 |
| 11100 | 0 |
| 11219 | 46 |
|------------|------------|
5 rows selected
This query returns transaction IDs and product IDs for records that contain a non-null product ID at the 21st position in the array.
Return clicks for a specific product range:
0: jdbc:drill:> select * from (select t.trans_id, t.trans_info.prod_id[0] as prodid,
t.trans_info.purch_flag as purchased
from `clicks/clicks.json` t) sq
where sq.prodid between 700 and 750 and sq.purchased='true'
order by sq.prodid;
|------------|------------|------------|
| trans_id | prodid | purchased |
|------------|------------|------------|
| 21886 | 704 | true |
| 20674 | 708 | true |
| 22158 | 709 | true |
| 34089 | 714 | true |
| 22545 | 714 | true |
| 37500 | 717 | true |
| 36595 | 718 | true |
...
This query assumes that there is some meaning to the array (that it is an ordered list of products purchased rather than a random list).
Perform Operations on Arrays
Rank successful click conversions and count product searches for each session:
0: jdbc:drill:> select t.trans_id, t.`date` as session_date, t.user_info.cust_id as
cust_id, t.user_info.device as device, repeated_count(t.trans_info.prod_id) as
prod_count, t.trans_info.purch_flag as purch_flag
from `clicks/clicks.json` t
where t.trans_info.purch_flag = 'true' order by prod_count desc;
|------------|--------------|------------|------------|------------|------------|
| trans_id | session_date | cust_id | device | prod_count | purch_flag |
|------------|--------------|------------|------------|------------|------------|
| 37426 | 2014-04-06 | 18709 | IOS5 | 34 | true |
| 31589 | 2014-04-16 | 18576 | IOS6 | 31 | true |
| 11600 | 2014-04-07 | 4260 | AOS4.2 | 28 | true |
| 35074 | 2014-04-03 | 16697 | AOS4.3 | 27 | true |
| 17192 | 2014-04-22 | 2501 | AOS4.2 | 26 | true |
...
This query uses an SQL extension, the repeated_count function, to get an aggregated count of the array values. The query returns the number of products searched for each session that converted into a purchase and ranks the counts in descending order. Only clicks that have resulted in a purchase are counted.
Store a Result Set in a Table for Reuse and Analysis
To facilitate additional analysis on this result set, you can easily and quickly create a Drill table from the results of the query.
Continue to use the dfs.clicks workspace
0: jdbc:drill:> use dfs.clicks;
|-------|-----------------------------------------|
| ok | summary |
|-------|-----------------------------------------|
| true | Default schema changed to [dfs.clicks] |
|-------|-----------------------------------------|
1 row selected (1.61 seconds)
Return product searches for high-value customers:
0: jdbc:drill:> select o.cust_id, o.order_total, t.trans_info.prod_id[0] as prod_id
from
hive.orders as o
join `clicks/clicks.json` t
on o.cust_id=t.user_info.cust_id
where o.order_total > (select avg(inord.order_total)
from hive.orders inord
where inord.state = o.state);
|----------|--------------|----------|
| cust_id | order_total | prod_id |
|----------|--------------|----------|
| 1328 | 73 | 26 |
| 1328 | 146 | 26 |
| 1328 | 56 | 26 |
| 1328 | 91 | 26 |
| 1328 | 74 | 26 |
...
|----------|--------------|----------|
107,482 rows selected (14.863 seconds)
This query returns a list of products that are being searched for by customers who have made transactions that are above the average in their states.
Materialize the result of the previous query:
0: jdbc:drill:> create table product_search as select o.cust_id, o.order_total, t.trans_info.prod_id[0] as prod_id
from
hive.orders as o
join `clicks/clicks.json` t
on o.cust_id=t.user_info.cust_id
where o.order_total > (select avg(inord.order_total)
from hive.orders inord
where inord.state = o.state);
|-----------|----------------------------|
| Fragment | Number of records written |
|-----------|----------------------------|
| 0_0 | 107482 |
|-----------|----------------------------|
1 row selected (3.488 seconds)
This example uses a CTAS statement to create a table based on a correlated subquery that you ran previously. This table contains all of the rows that the query returns (107,482) and stores them in the format specified by the storage plugin (Parquet format in this example). You can create tables that store data in csv, parquet, and json formats.
Query the new table to verify the row count:
This example simply checks that the CTAS statement worked by verifying the number of rows in the table.
0: jdbc:drill:> select count(*) from product_search;
|---------|
| EXPR$0 |
|---------|
| 107482 |
|---------|
1 row selected (0.155 seconds)
Find the storage file for the table:
[root@maprdemo product_search]# cd /mapr/demo.mapr.com/data/nested/product_search
[root@maprdemo product_search]# ls -la
total 451
drwxr-xr-x. 2 mapr mapr 1 Sep 15 13:41 .
drwxr-xr-x. 4 root root 2 Sep 15 13:41 ..
-rwxr-xr-x. 1 mapr mapr 460715 Sep 15 13:41 0_0_0.parquet
Note that the table is stored in a file called 0_0_0.parquet. This file is
stored in the location defined by the dfs.clicks workspace:
"location": "http://demo.mapr.com/data/nested"
There is a subdirectory that has the same name as the table you created.
What’s Next
Complete the tutorial with the Summary.