
Wikipedia Edit History
Quick Stats
The Wikipedia Edit History is a public dump of the website made available by the wikipedia foundation. You can find details here. The dumps are made available as SQL or XML dumps. You can find the entire schema drawn together in this great diagram.
{kind=link}
Approach
The main distribution files are:
- Current Pages: As of January 2013 this SQL dump was 9.0GB in its compressed format.
- Complere Archive: This is what we actually want, but at a size of multiple terrabytes, clearly exceeds the storage available at home.
To have some real historic data, it is recommended to download a Special Export use this link. Using this tool you generate a category specific XML dump and configure various export options. There are some limits like a maximum of 1000 revisions per export, but otherwise this should work out just fine.
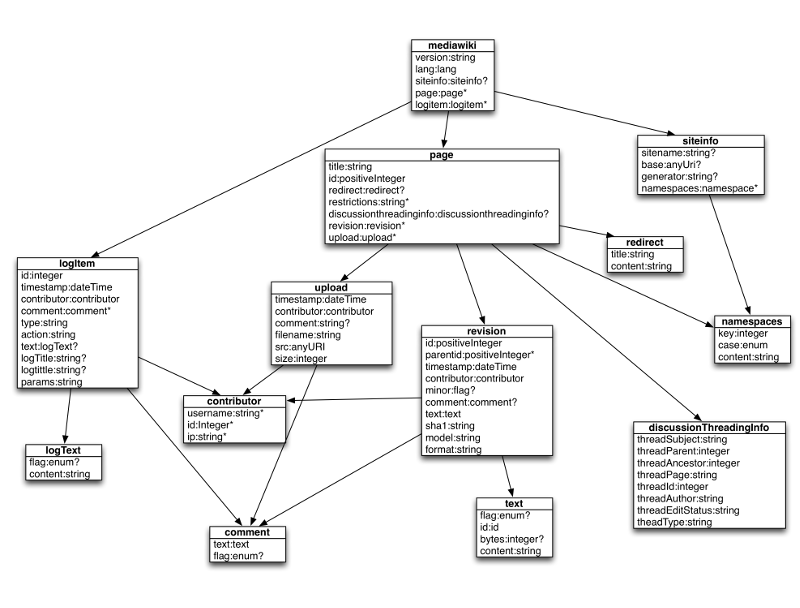
The entities used in the query use cases.
Use Cases
Select Change Volume Based on Time
Query
select rev.::parent.title, rev.::parent.id, sum(rev.text.bytes)
from mediawiki.page.revision as rev
where rev.timestamp.between(?, ?)
group by rev.::parent;
Explanation: This is my attempt in mixing records and structures. The from
statement refers to mediawiki as a record type / row, but also mixes in
structural information, i.e. page.revision, internal to the record. The
query now uses page.revision as base to all other statements, in this case
the select, where and the group by. The where statement again uses a
JSON like expression to state, that the timestamp must be between two values,
paramaeters are written as question marks, similar to JDBC. The group by
statement instructs the query to aggregate results based on the parent of a
revision, in this case a page. The ::parent syntax is borrowed from
XPath. As we are aggregating on page it is safe to select the title and
id from the element in the select. We also use an aggregation function to
add the number of bytes changed in the given time frame, this should be self
explanatory.
Discussion:
- I am not very satisfied using the
::syntax, as it is ugly. We probably wont need that many axis specifiers, e.g. we dont need any attribute specifiers, but for now, I could not think of anything better, - Using an
asexpression in thefromstatement is optional, you would simply have to replace all references torevwithrevision. - I am not sure if this is desired, but you cannot see on first glance, where the hierarchical stuff starts. This may be confusing to a RDBMS purist, at least it was for me at the beginning. But now I think this strikes the right mix between verbosity and elegance.
- I assume we would need some good indexing, but this should be achievable. We would need to translate the relative index
rev.timestampto an record absolute index$.mediawiki.page.revision.timestamp. Unclear to me now is whether the index would point to the record, or would it point to some kind of record substructure?
Select Change Volume Aggregated on Time
Query
select rev.::parent.title, rev.::parent.id, sum(rev.text.bytes), rev.timestamp.monthYear()
from mediawiki.page.revision as rev
where rev.timestamp.between(?, ?)
group by rev.::parent, rev.timestamp.monthYear()
order by rev.::parent.id, rev.timestamp.monthYear();
Explanation: This is refinement of the previous query. In this case we are
again returning a flat list, but are using an additional scalar result and
group statement. In the previous example we were returning one result per
found page, now we are returning one result per page and month of changes.
Order by is nothing special, in this case.
Discussion:
- I always considered mySQL confusing using implicit group by statements, as I prefer fail fast mechanisms. Hence I would opt for explicit
group byoperators. - I would not provide implicit nodes into the records, i.e. if you want some attribute of a timestamp, call a function and not expect an automatically added element. So we want
rev.timestamp.monthYear()and notrev.timestamp.monthYear. This may be quite confusing, especially if we have heterogenous record structures. We might even go ahead and support namespaces for custom, experimental features likerev.timestamp.custom.maya:doomsDay().
Select Change Volume Based on Contributor
Query
select ctrbr.username, ctbr.ip, ctbr.userid, sum(ctbr::parent.bytes) as bytesContributed
from mediawiki.page..contributor as ctbr
group by ctbr.canonize()
order by bytesContributed;
Explanation: This query looks quite similar to the previous queries, but I added this one nonetheless, as it hints on an aggregation which may spawn multiple records. The previous examples were based on pages, which are unique to a record, where as the contributor may appear many times in many different records.
Discussion:
- I have added the
..operator in this example. Besides of being syntactic sugar, it also allows us to search forrevisionanduploadwhich are both children ofpageand may both have acontributor. The more RBMS like alternative would be aunion, but this was not natural enough. - I am sure the
ctbr.canonize()will cause lots of discussions :-). The thing is, that a contributor may repeat itself in many different records, and we dont really have an id. If you look at the wikimedia XSD, all three attributes are optional, and the data says the same, so we cannot just simply sayctbr.userid. Hence the canonize function should create a scalar value containing all available information of the node in a canonical form. - Last but not least, I always hated, that mySQL would not be able to reuse column definitions from the
selectstatement in theorderstatements. So I added on my wishlist, that thebytesContributeddefinition is reusable.