
Querying Directories
You can store multiple files in a directory and query them as if they were a single entity. You do not have to explicitly join the files. The files must be compatible, in the sense that they must have comparable data types and columns in the same order. Hidden files that do not have comparable data types can cause a Table Not Found error. You can query directories of files that have formats supported by Drill, such as JSON, Parquet, or text files.
For example, assume that a testdata directory contains two files with the
same structure: plays.csv and moreplays.csv. The first file contains 7
records and the second file contains 3 records. The following query returns
the “union” of the two files, ordered by the first column:
0: jdbc:drill:zk=local> SELECT COLUMNS[0] AS `Year`, COLUMNS[1] AS Play
FROM dfs.`/Users/brumsby/drill/testdata` order by 1;
|------------|------------------------|
| Year | Play |
|------------|------------------------|
| 1594 | Comedy of Errors |
| 1595 | Romeo and Juliet |
| 1596 | The Merchant of Venice |
| 1599 | As You Like It |
| 1599 | Hamlet |
| 1601 | Twelfth Night |
| 1606 | Macbeth |
| 1606 | King Lear |
| 1609 | The Winter's Tale |
| 1610 | The Tempest |
|------------|------------------------|
10 rows selected (0.296 seconds)
You can drill down further and automatically query subdirectories as well. For example, assume that you have a logs directory that contains a subdirectory for each year and subdirectories for each month (1 through 12). The month directories contain JSON files.
[root@ip-172-16-1-200 logs]# pwd
/mapr/drilldemo/labs/clicks/logs
[root@ip-172-16-1-200 logs]# ls
2012 2013 2014
[root@ip-172-16-1-200 logs]# cd 2013
[root@ip-172-16-1-200 2013]# ls
1 10 11 12 2 3 4 5 6 7 8 9
You can query all of these files, or a subset, by referencing the file system
once in a Drill query. For example, the following query counts the number of
records in all of the files inside the 2013 directory:
0: jdbc:drill:> SELECT COUNT(*) FROM MFS.`/mapr/drilldemo/labs/clicks/logs/2013` ;
|------------|
| EXPR$0 |
|------------|
| 24000 |
|------------|
1 row selected (2.607 seconds)
Querying Partitioned Directories
You can use special variables in Drill to refer to subdirectories in your workspace path, for example:
- dir0
- dir1
- …
Note that these variables are dynamically determined based on the partitioning of the file system. No up-front definitions are required to identify the partitions that exist.
The following image represents a partitioned directory and shows a query on the directory using variables:
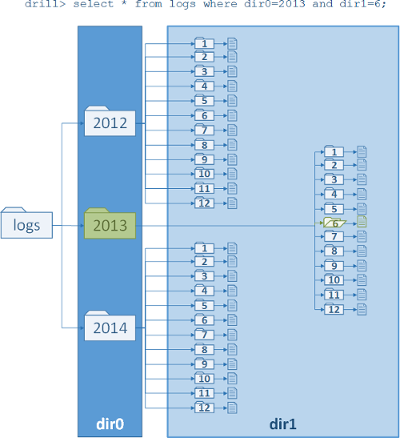
When you use directory variables in a query, note that the variables are relative to the root directory used in the FROM clause. For example, let’s say you create a workspace within the dfs storage plugin named logs (dfs.logs) that points to the /tmp directory in the file system. The /tmp directory contains a /logs directory (/tmp/logs) with the same subdirectories shown in the example image above. You can query the data in the /logs directory using variables, as shown in the following examples:
use dfs.logs;
|------|--------------------------------------|
| ok | summary |
|------|--------------------------------------|
| true | Default schema changed to [dfs.logs] |
|------|--------------------------------------|
//The following query constrains files inside the subdirectory named 2013. The variable dir0 refers to the first level down from logs (root directory).
select * from logs where dir0='2013' limit 3;
|------|------|--------------------------------------|----|------------|-----------|-------------------------|--------|----------------|------------------|-----------|-----------|-----------|---------------------|----------|
| dir0 | dir1 | registration_dttm | id | first_name | last_name | email | gender | ip_address | cc | country | birthdate | salary | title | comments |
|------|------|--------------------------------------|----|------------|-----------|-------------------------|--------|----------------|------------------|-----------|-----------|-----------|---------------------|----------|
| 2013 | 1 | \x00*\xE9l\xF2\x19\x00\x00N\x7F%\x00 | 1 | Amanda | Jordan | ajordan0@com.com | Female | 1.197.201.2 | 6759521864920116 | Indonesia | 3/8/1971 | 49756.53 | Internal Auditor | 1E+02 |
| 2013 | 1 | \x00^0\xD0\xE17\x00\x00N\x7F%\x00 | 2 | Albert | Freeman | afreeman1@is.gd | Male | 218.111.175.34 | | Canada | 1/16/1968 | 150280.17 | Accountant IV | |
| 2013 | 1 | \x00.\xF9"\xCB\x03\x00\x00N\x7F%\x00 | 3 | Evelyn | Morgan | emorgan2@altervista.org | Female | 7.161.136.94 | 6767119071901597 | Russia | 2/1/1960 | 144972.51 | Structural Engineer | |
|------|------|--------------------------------------|----|------------|-----------|-------------------------|--------|----------------|------------------|-----------|-----------|-----------|---------------------|----------|
//The following query constrains files inside the subdirectory named 1. The variable dir0 refers to the first level down from 2013 (the root directory now).
select * from `logs/2013` where dir0='1' limit 3;
|------|--------------------------------------|----|------------|-----------|-------------------------|--------|----------------|------------------|-----------|-----------|-----------|---------------------|----------|
| dir0 | registration_dttm | id | first_name | last_name | email | gender | ip_address | cc | country | birthdate | salary | title | comments |
|------|--------------------------------------|----|------------|-----------|-------------------------|--------|----------------|------------------|-----------|-----------|-----------|---------------------|----------|
| 1 | \x00*\xE9l\xF2\x19\x00\x00N\x7F%\x00 | 1 | Amanda | Jordan | ajordan0@com.com | Female | 1.197.201.2 | 6759521864920116 | Indonesia | 3/8/1971 | 49756.53 | Internal Auditor | 1E+02 |
| 1 | \x00^0\xD0\xE17\x00\x00N\x7F%\x00 | 2 | Albert | Freeman | afreeman1@is.gd | Male | 218.111.175.34 | | Canada | 1/16/1968 | 150280.17 | Accountant IV | |
| 1 | \x00.\xF9"\xCB\x03\x00\x00N\x7F%\x00 | 3 | Evelyn | Morgan | emorgan2@altervista.org | Female | 7.161.136.94 | 6767119071901597 | Russia | 2/1/1960 | 144972.51 | Structural Engineer | |
|------|--------------------------------------|----|------------|-----------|-------------------------|--------|----------------|------------------|-----------|-----------|-----------|---------------------|----------|
Starting in Drill 1.16, Drill uses a Value operator instead of a Scan operator to read data when a query selects on partitioned columns (dir0, dir1, …dirN) only and also has a DISTINCT or GROUP BY operation. Instead of scanning all directory columns, Drill either reads the specified column from the metadata cache file (if one exists) or Drill selects directly from the directory (partition location). The presence of the Values operator (instead of the Scan operator) in the query plan indicates that Drill is using this optimization, as shown in the following examples:
select distinct dir0 from `/logs`;
------
dir0
------
2012
2013
2014
------
explain plan for select distinct dir0 from `/logs`;
------------------------------------------------------------------------------------------------------------------------------------------------------------------|
text json
------------------------------------------------------------------------------------------------------------------------------------------------------------------|
00-00 Screen
00-01 Project(dir0=[$0])
00-02 StreamAgg(group=[{0}])
00-03 Sort(sort0=[$0], dir0=[ASC])
00-04 Values(tuples=[[{ '2012' }, { '2012' }, { '2013' }, { '2012' }, { '2014' }, { '2012' }]])
select dir0 from `/logs` group by dir0;
------
| dir0 |
------
| 2012 |
| 2013 |
| 2014 |
------
explain plan for select dir0 from `/logs` group by dir0;
------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| text | json |
------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 00-00 Screen
00-01 Project(dir0=[$0])
00-02 StreamAgg(group=[{0}])
00-03 Sort(sort0=[$0], dir0=[ASC])
00-04 Values(tuples=[[{ '2012' }, { '2012' }, { '2013' }, { '2012' }, { '2014' }, { '2012' }]])
You can use query directory functions to restrict a query to one of a number of subdirectories and to prevent Drill from scanning all data in directories.
Querying Multiple Directories in One Query by Wildcard Matching
You can query multiple directories and multiple files in one query with the help of Wildcard Matching conveniently.
-
Query a set of directories:
SELECT * FROM dfs.`multilevel/parquet/{1994,1995}`; -
Query all files in a directory:
SELETCT * FROM dfs.`multilevel/parquet/1994/*`; -
Query multiple directories by single character wildcard matching:
SELECT * FROM dfs.`multilevel/parquet/199?/*` -
Query multiple directories by single character range wildcard matching:
SELECT * FROM dfs.`multilevel/parquet/199[4-5]/*`